OpenCV的安装
国内一些pip的镜像源:
阿里云 https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
1 | (base)$ conda create -n py365 python=3.6.5 # anaconda中创建python版本为3.7.3的虚拟环境 |
内容完善中……
图像金字塔
高斯金字塔
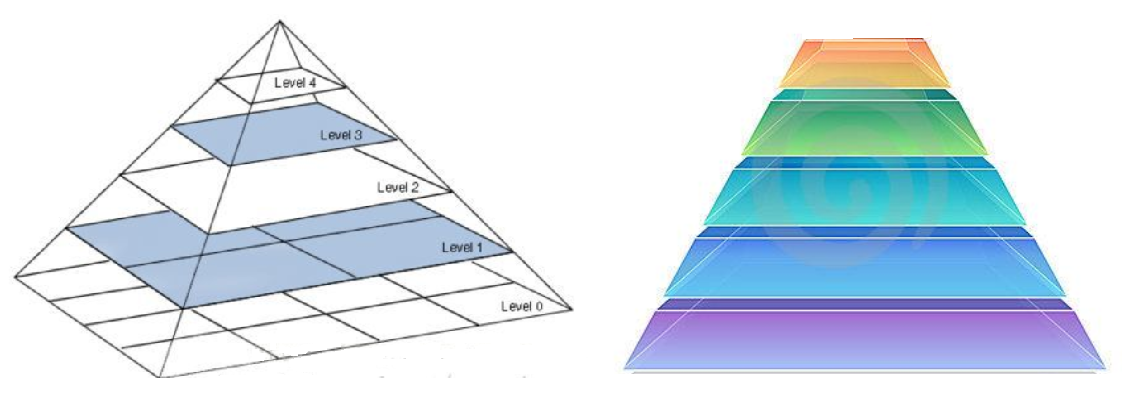
高斯金字塔:向下采样法(缩小)

实例:
1 | img = cv2.imread("A.png") |
高斯金字塔:向上采样法(放大)
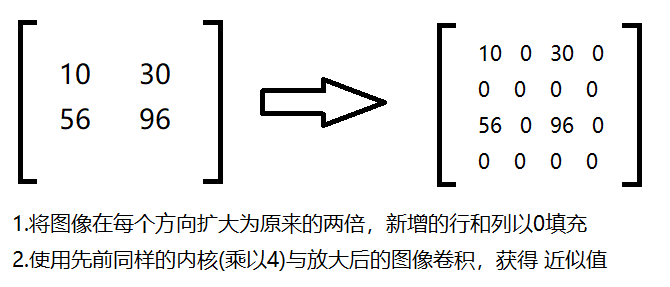
实例:
1 | img = cv2.imread("A.png") |
拉普拉斯金字塔
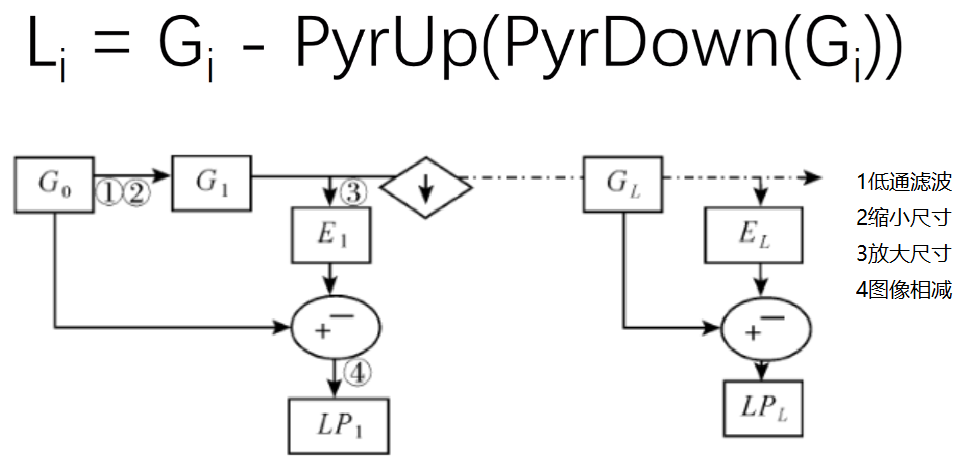
1 | down=cv2.pyrDown(img) |
轮廓检测
cv2.findContours(img,mode,method)
mode:轮廓检索模式
- RETR_EXTERNAL :只检索最外面的轮廓;
- RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
- RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
- RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;
method:轮廓逼近方法
- CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
- CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
为了得到更高的准确率,使用二值图像。
1 | img = cv2.imread('contours.png') |
轮廓特征
炬
面积
1 | cnt = contours[0] |
周长
1 | cnt = contours[0] |
轮廓近似

1 | # 找轮廓 |
1 | epsilon = 0.15*cv2.arcLength(cnt,True) # epsilon一般按照周长的百分比进行设置,越小,轮廓近似值越大 |
边界矩形
1 | img = cv2.imread('contours.png') |
1 | area = cv2.contourArea(cnt) |
最小外接圆
1 | (x,y),radius = cv2.minEnclosingCircle(cnt) |
轮廓的性质
Solidty
Equivalent Diameter
方向
掩模和像素点
平均颜色和平均灰度
极点
模版匹配
模版匹配和卷积原理很像,模版在原图上从原点开始滑动,计算模版与(图像被模版覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里有6种。然后将每次计算的结果放入一个矩阵里,作为结果输出。假如原图形是A✖️B大小,而模版是a✖️b的大小,则输出结果的矩阵是(A-a+1)✖️(B-b+1)的大小。
- TM_SQDIFF:计算平方差,计算出来的值越小,越相关
- TM_CCORR:计算相关性,计算出来的值越大,越相关
- TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
- TM_SQDIFF_NORMED:计算归一化平方差,计算出来的值越接近0,越相关
TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
1 | img = cv2.imread("lena.jpg",0) |
1 | # 匹配多个对象 |
直方图
统计图中的像素点分布。
直方图的计算、绘制与分析
cv2.calcHist(images, channels,mask,histSize,range)
- images:原图像格式为uint8或float32,当传入函数时应用中括号,例如[img]
- channels:同样用中括号,如果图像时灰度图,它的值是[0],如果是彩色图像,那传入的参数可以是【0】【1】【2】
- mask:掩模图像,统计整幅图像就将它设为None,但是如果只想统计一部分,就制作一个掩模。
- histSize:BIN的数目,也用中括号
- ranges:像素值范围,为[0,256]
1 | img = cv2.imread("cat.png",0) |
mask操作
1 | # 创建mask |
直方图均衡化
均衡后,色彩和亮度能够稍微的提升。
1 | equ = cv2.equalizeHist(img) |
- 自适应直方图均衡化
1 | clahe = cv2.createCLAHE(clipLimit=2.0,tilerGridSize(8,8)) |
傅立叶变换
中心思想:任何函数都能通过傅立叶堆叠出来。
以时间为参照就是时域分析。
傅立叶变换的作用:
- 高频:变化剧烈的灰度分量,例如边界
- 低频:变化缓慢的灰度分量,例如一片大海
可以找到图像中的高频与低频部分。
滤波:
- 低通滤波器:只保留低频,会使图像模糊
- 高通滤波器:只保留高频,会使图像细节增强
1 | import numpy as np |
图像特征
Harris角点检测
边界:一个特征值大,一个特征值小,自相关函数值在某一方向上大,在其他方向上小。
平面:两个特征值都小,且近似相等,自相关函数数值在各个方向上都小。
角点:两个特征值都大,且近似相等,自相关函数在所有方向都增大。
cv2.cornerHarris()
- img: 数据类型为 float32 的入图像
- blockSize: 角点检测中指定区域的大小
- ksize: Sobel求导中使用的窗口大小
- k: 取值参数为 [0,04,0.06]
1 | dst = cv2.cornerHarris(gray, 2, 3, 0.04) |
1 | img[dst>0.01*dst.max()]=[0,0,255] #大于最大值的0.01倍,就认为是一个角点 |
Sift特征
Scale Invariant Feature Transform
图像尺度空间
在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同的尺度下都存在的特点。
尺度空间的获取通常使用高斯模糊来实现。
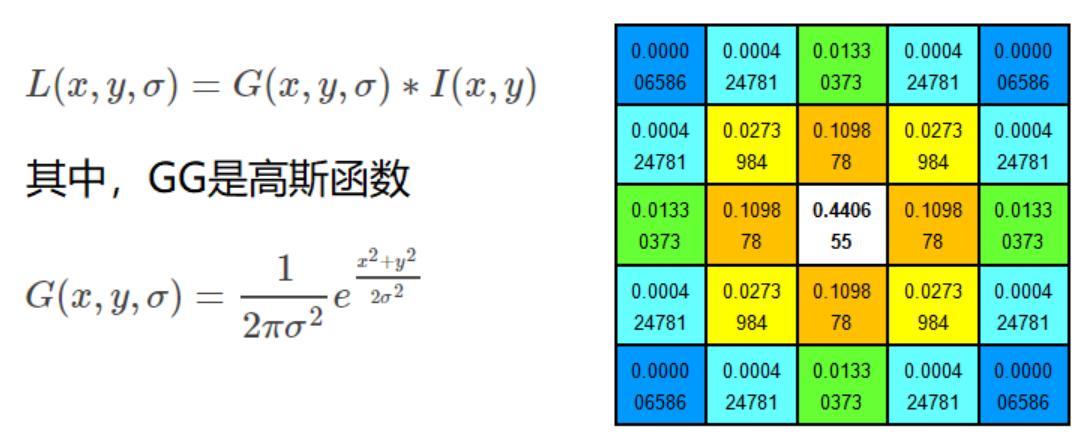

不同σ的高斯函数决定了对图像的平滑程度,越大的σ值对应的图像越模糊。
多分辨率金字塔
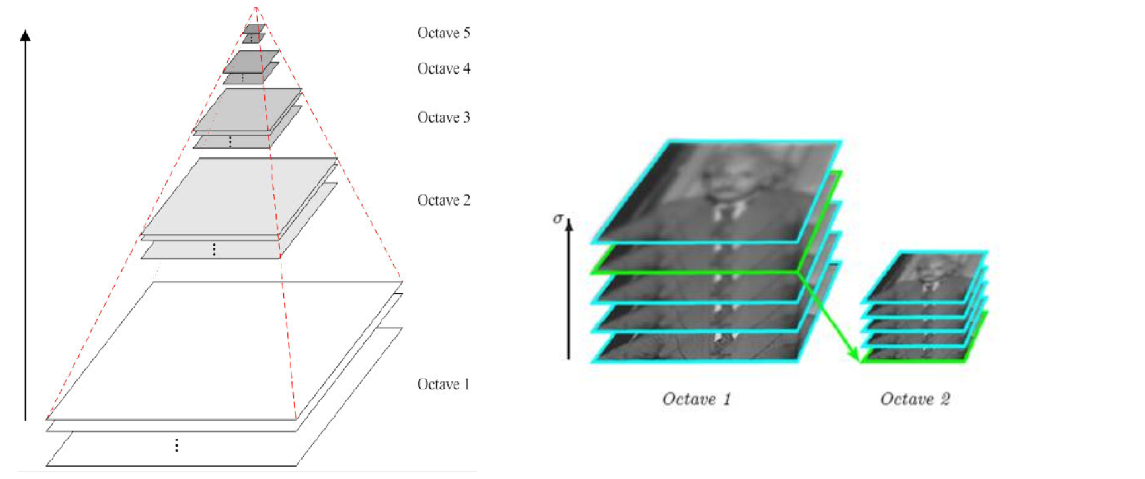
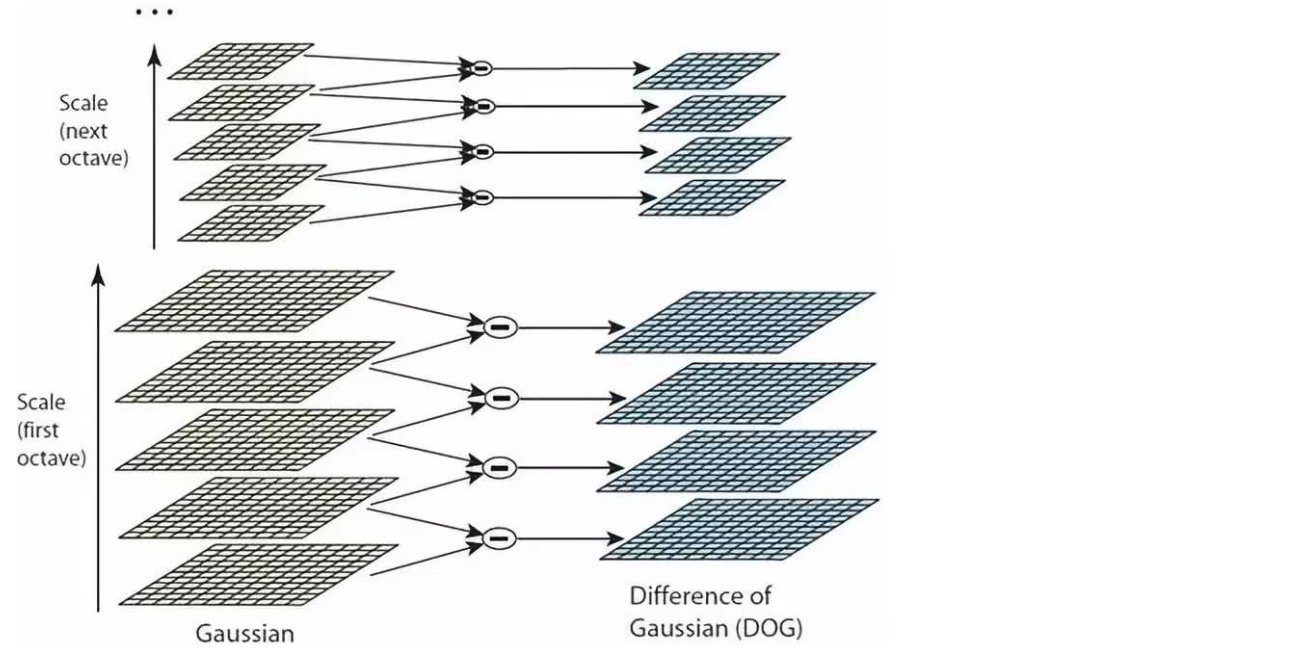
高斯差分金字塔(DOG)
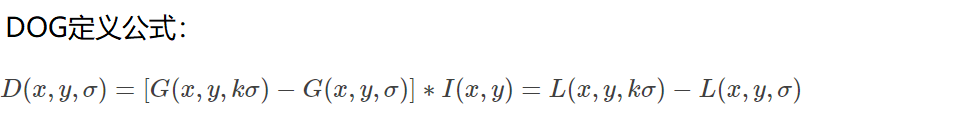
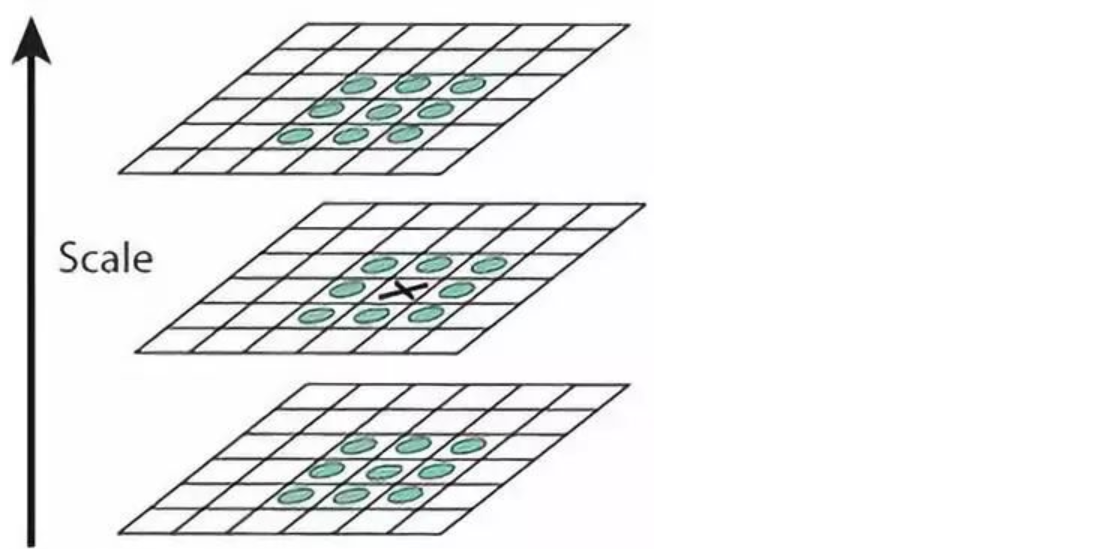
DoG空间极值检测
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。如下图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较。
关键点的精确定位
这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点,精确定位极值点的一种方法是,对尺度空间DoG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
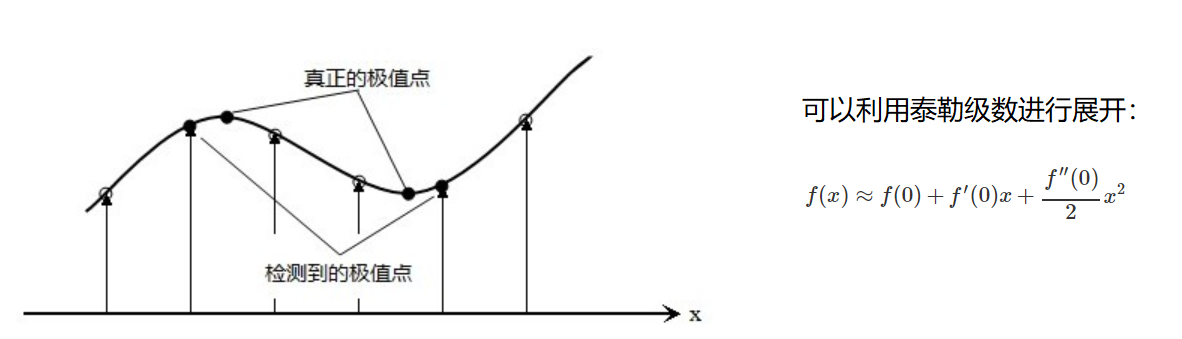
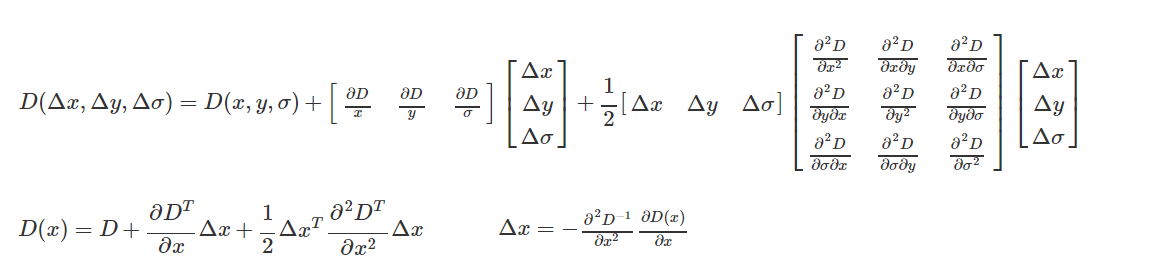
消除边界响应

特征点的主方向

每个特征点可以得到三个信息(x,y,σ,θ),即位置、尺度和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
生成特征描述
在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。
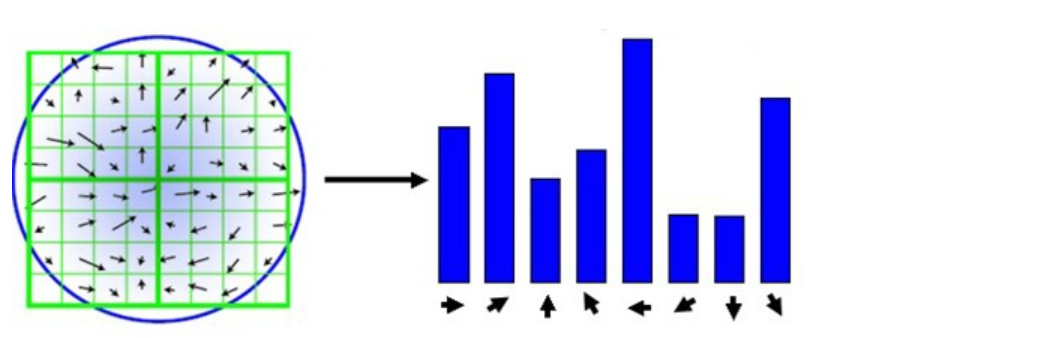
为了保证特征矢量的旋转不变性,要以特征点为中心,在附近邻域内将坐标轴旋转θ角度,即将坐标轴旋转为特征点的主方向。
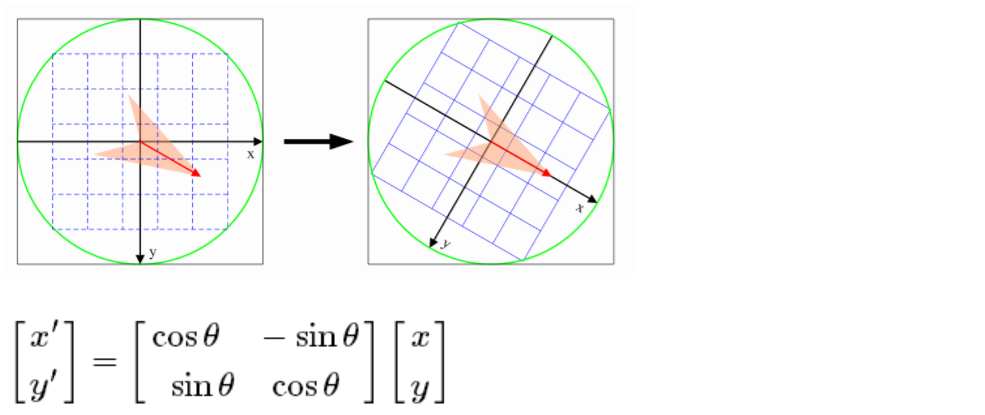
旋转之后的主方向为中心取8x8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4x4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征的由4个种子点组成,每个种子点有8个方向的向量信息。
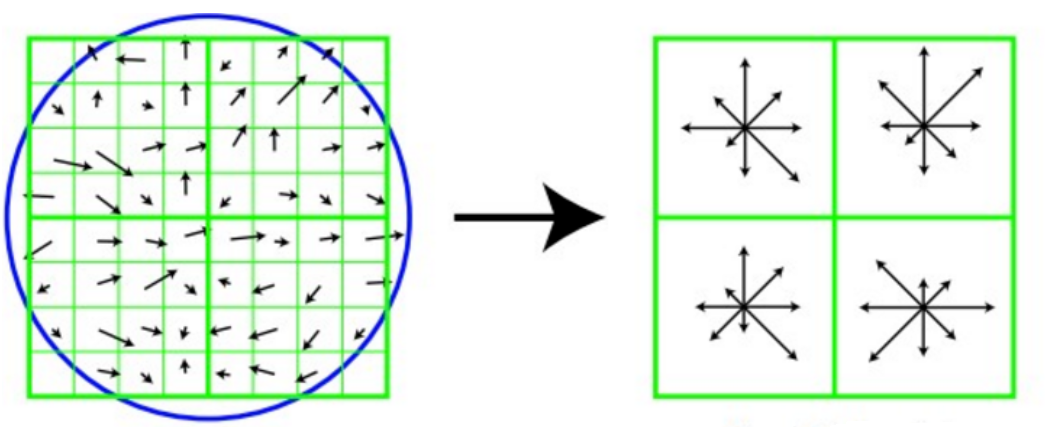
论文中建议对每个关键点使用4x4共16个种子点来描述,这样一个关键点就会产生128维的SIFT特征向量。
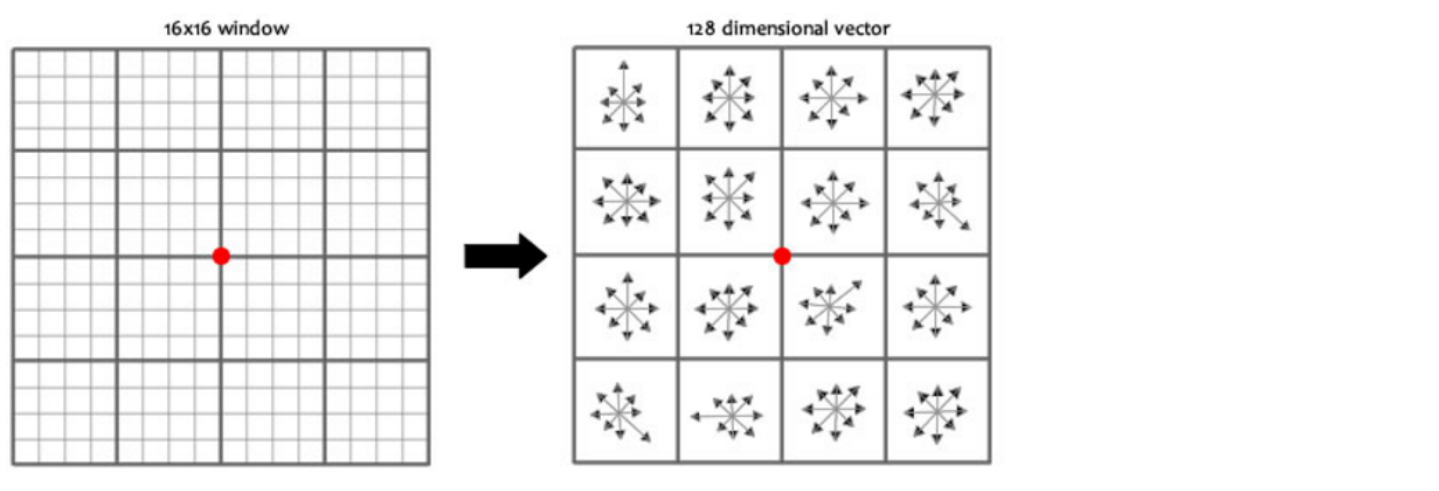
OpenCV SIFT函数
1 | import cv2 |
计算特征
1 | kp, des = sift.compute(gray, kp) |
1 | print (np.array(kp).shape) |
1 | des.shape |
1 | des[0] |
背景建模
帧差法
由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。

帧差法非常简单,但是会引入噪音和空洞问题。
混合高斯模型
(视频变化趋势应该是符合高斯分布的)
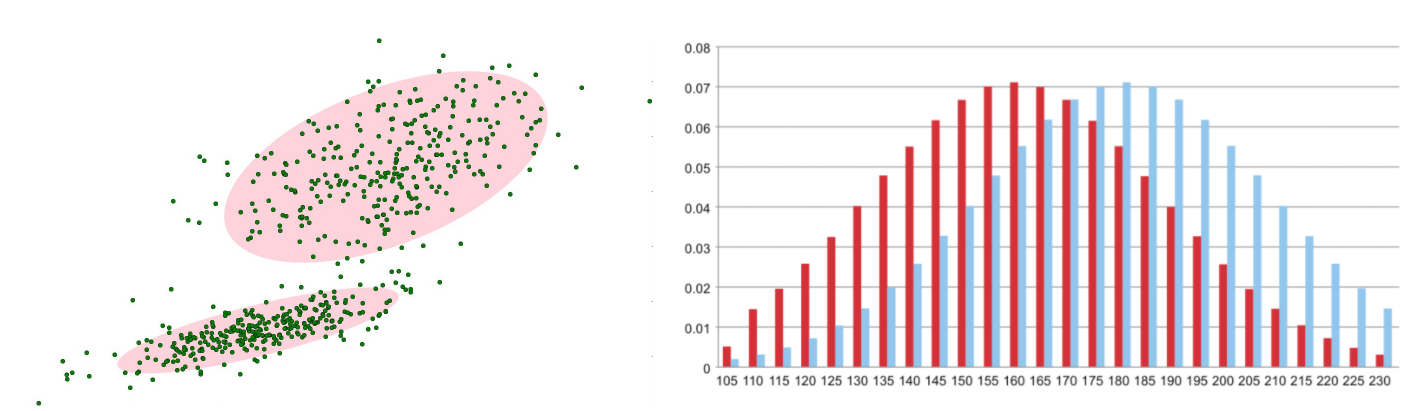
在进行前景检测前,先对背景进行训练,对图像中每个背景采用一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应。然后在测试阶段,对新来的像素进行GMM匹配,如果该像素值能够匹配其中一个高斯,则认为是背景,否则认为是前景。由于整个过程GMM模型在不断更新学习中,所以对动态背景有一定的鲁棒性。最后通过对一个有树枝摇摆的动态背景进行前景检测,取得了较好的效果。
在视频中对于像素点的变化情况应当是符合高斯分布。
背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型也可以带有权重。
混合高斯模型学习方法
- 1.首先初始化每个高斯模型矩阵参数。
- 2.取视频中T帧数据图像用来训练高斯混合模型。来了第一个像素之后用它来当做第一个高斯分布。
- 3.当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3倍的方差内,则属于该分布,并对其进行参数更新。
- 4.如果下一次来的像素不满足当前高斯分布,用它来创建一个新的高斯分布。
混合高斯模型测试方法
在测试阶段,对新来像素点的值与混合高斯模型中的每一个均值进行比较,如果其差值在2倍的方差之间的话,则认为是背景,否则认为是前景。将前景赋值为255,背景赋值为0。这样就形成了一副前景二值图。

1 | import numpy as np |
光流估计
光流是空间运动物体在观测成像平面上的像素运动的“瞬时速度”,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如目标跟踪。
- 亮度恒定:同一点随着时间的变化,其亮度不会发生改变。
- 小运动:随着时间的变化不会引起位置的剧烈变化,只有小运动情况下才能用前后帧之间单位位置变化引起的灰度变化去近似灰度对位置的偏导数。
- 空间一致:一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。因为光流法基本方程约束只有一个,而要求x,y方向的速度,有两个未知变量。所以需要连立n多个方程求解。
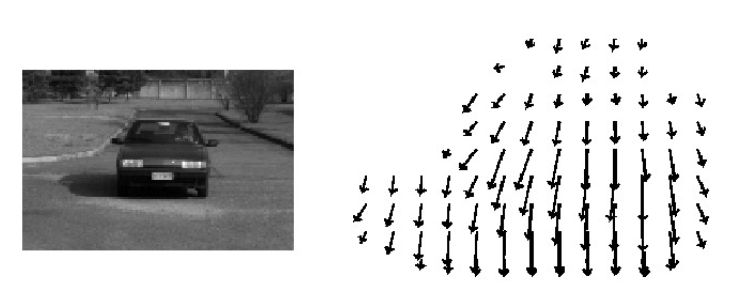

Lucas-Kanade 算法
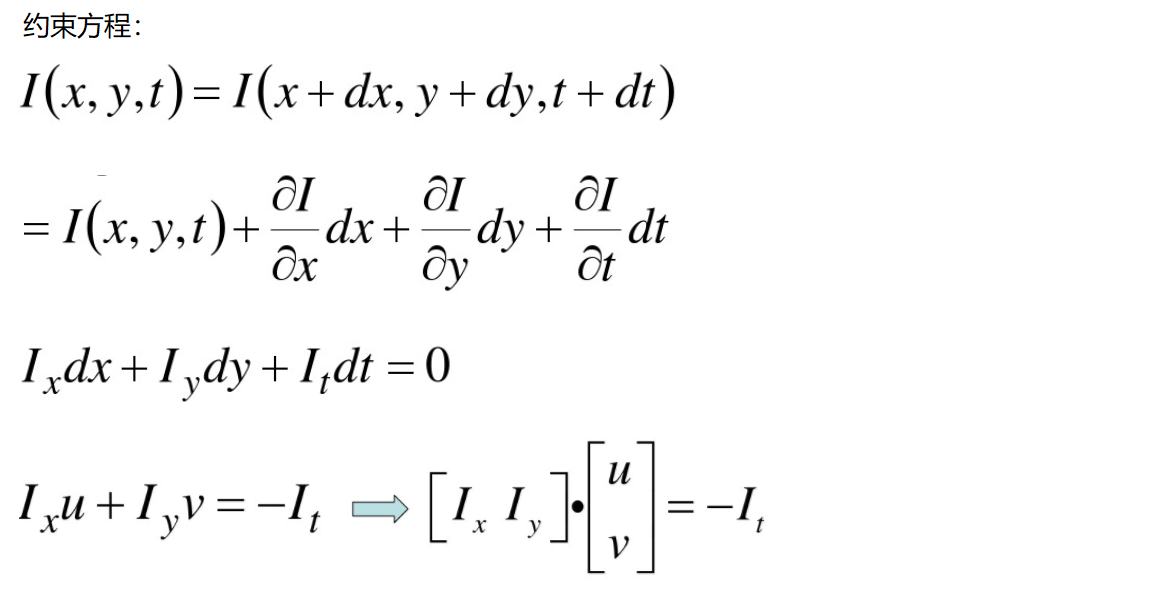
如何求解方程组呢?看起来一个像素点根本不够,在物体移动过程中还有哪些特性呢?
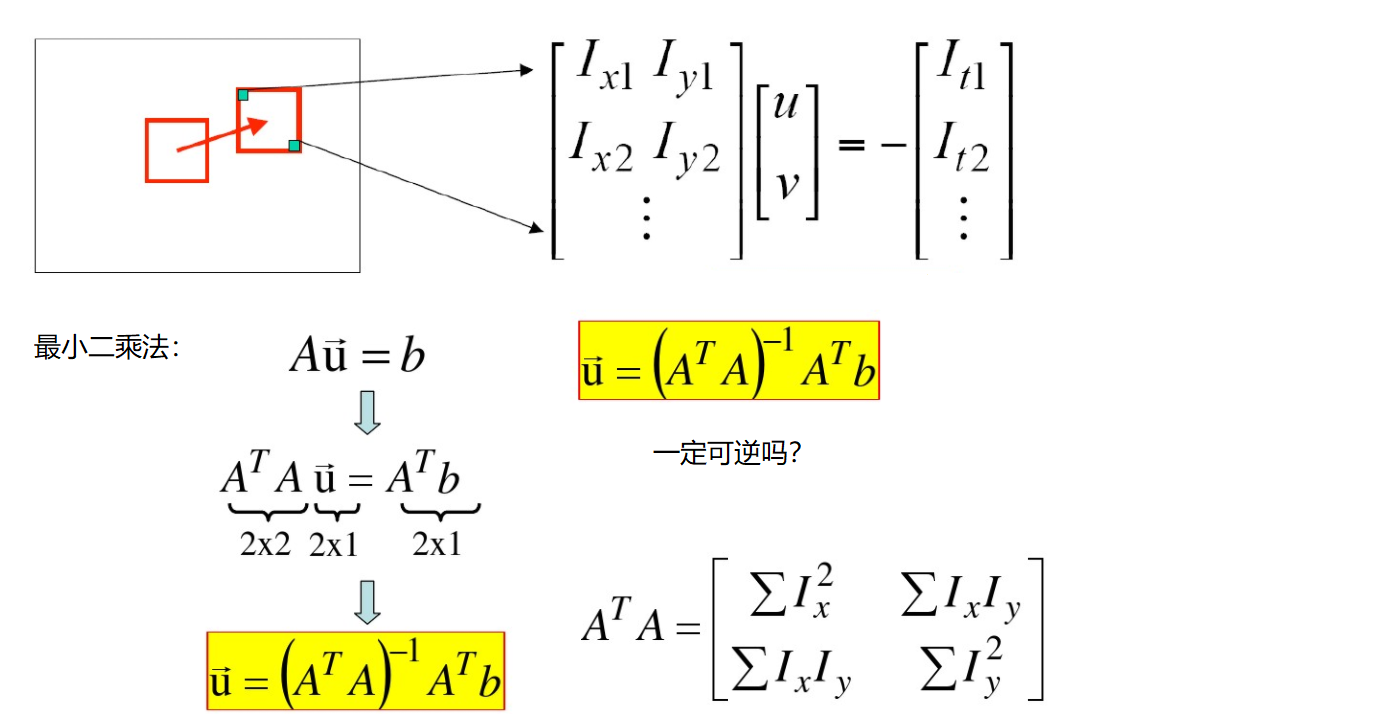
cv2.calcOpticalFlowPyrLK():
参数:
- prevImage 前一帧图像
- nextImage 当前帧图像
- prevPts 待跟踪的特征点向量
- winSize 搜索窗口的大小
- maxLevel 最大的金字塔层数
返回:
- nextPts 输出跟踪特征点向量
- status 特征点是否找到,找到的状态为1,未找到的状态为0
1 | import numpy as np |
DNN模块
1 | """ |
图像基本操作
图像阈值
简单阈值
自适应阈值
Otsu‘s 二值化
平滑处理
平均
高斯模糊
中值模糊
双边滤波
形态学处理
腐蚀
膨胀
开运算
闭运算
梯度
礼帽
黑帽
梯度处理
边缘检测就是检测出图像上的边缘信息
1.导数,连续函数上某点斜率,导数越大表示变化率越大,变化率越大的地方就越是“边缘”,但是在计算机中不常用,因为在斜率90度的地方,导数无穷大,计算机很难表示这些无穷大的东西。
2.微分,连续函数上x变化了dx,导致y变化了dy,dy值越大表示变化的越大,那么计算整幅图像的微分,dy的大小就是边缘的强弱了。
微分与导数的关系:dy = f ‘(x) dx
Sobel算子和Scharr算子
基于一阶微分
中心点 f(x, y) 是重点考虑的,它的权重应该多一些,所以改进成下面这样的
1 | -1, 0, 1 |
这就是 Sobel 边缘检测算子,偏 x 方向的。
1 | -1, -2, -1 |
laplacian算子
拉普拉斯是用二阶差分计算边缘的
1 | 0, 1, 0 |
考虑两个斜对角的情况
1 | 1, 1, 1 |
Canny边缘检测
Canny边缘检测的步骤:
1.消除噪声:一般情况下,使用高斯平滑滤波器卷积降噪。
2.计算梯度幅值和方向。此时,按照Sobel滤波器的步骤。
怎么表征这种灰度值的变化呢?这里想到的就是导数微分,导数就是表征变化率的,但是数字图像都是离散的,也就是导数肯定会用差分来替代。用相邻像素的差分来计算梯度的大小和方向。
然后我们可以计算图像中每个像素的梯度大小为$G=\sqrt{G_x^2+G_y^2}$,梯度方向为$\theta=arctan(G_x/G_y)$
3.非极大值抑制。这一步排除非边缘像素,仅仅保留了一些细线条(候选边缘)。
对规定方向以外的梯度方向进行最大抑制。
理论上图像梯度幅值的元素值越大,说明图像中该点的梯度值越大,但这不能说明该点就是边缘。非极大值抑制是进行边缘检测的重要步骤,寻找像素点的局部最大值,沿着梯度方向,比较它前面和后面的梯度值,若梯度值局部最大则有可能为边缘像素,进行保留,否则就进行抑制(置为0)。

4.滞后阈值:Canny使用了滞后阈值,滞后阈值需要两个阈值(高阈值和低阈值):用双阈值算法检测和连接边缘。(保证了低错误率:与Sobel之间的区别)
a.如果某一像素位置的幅值超过高阈值,该像素被保留为边缘像素。
b.如果某一像素位置的幅值小于低阈值,该像素被排除。
c.如果某一像素位置的幅值在两个阈值之间,该像素仅仅在连接到一个高于阈值的像素时被保留。
Canny推荐的高低阈值比在2:1到3:1之间。

三个算子区别
sobel 产生的边缘有强弱,抗噪性好
laplace 对边缘敏感,可能有些是噪声的边缘,也被算进来了
canny 产生的边缘很细,可能就一个像素那么细,没有强弱之分。
边缘检测
Hough变换
直线变换
- 基本思想
主要原理是对于边缘的每一个像素点(x0,y0),把可能经过它的所有直线,映射到仿射参数空间(即hough space),然后投票,每次有直线方程满足($\theta$,$r_\theta$),此处
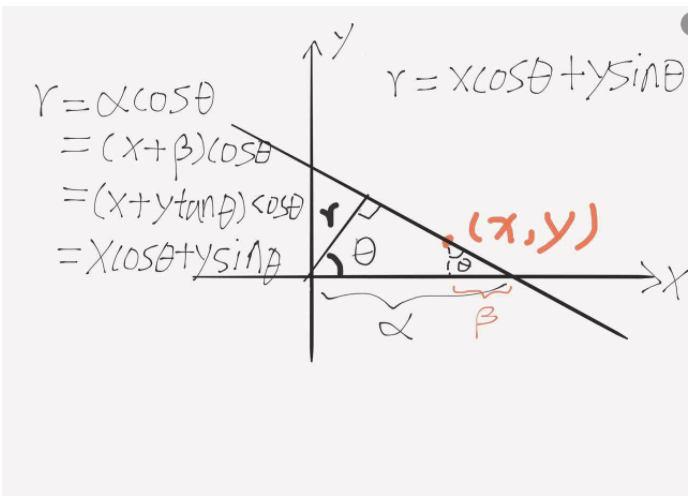
- 详细推导
它追踪图像中每个点对应曲线间的交点. 如果交于一点的曲线的数量超过了阈值, 那么可以认为这个交点所代表的参数对($\theta$,$r_\theta$)在原图像中为一条直线。
对图像做霍夫变换,也就是分别代入霍夫变换公式
$r = xcos\theta + ysin\theta$
在仿射参数空间的结果是这个样子的:
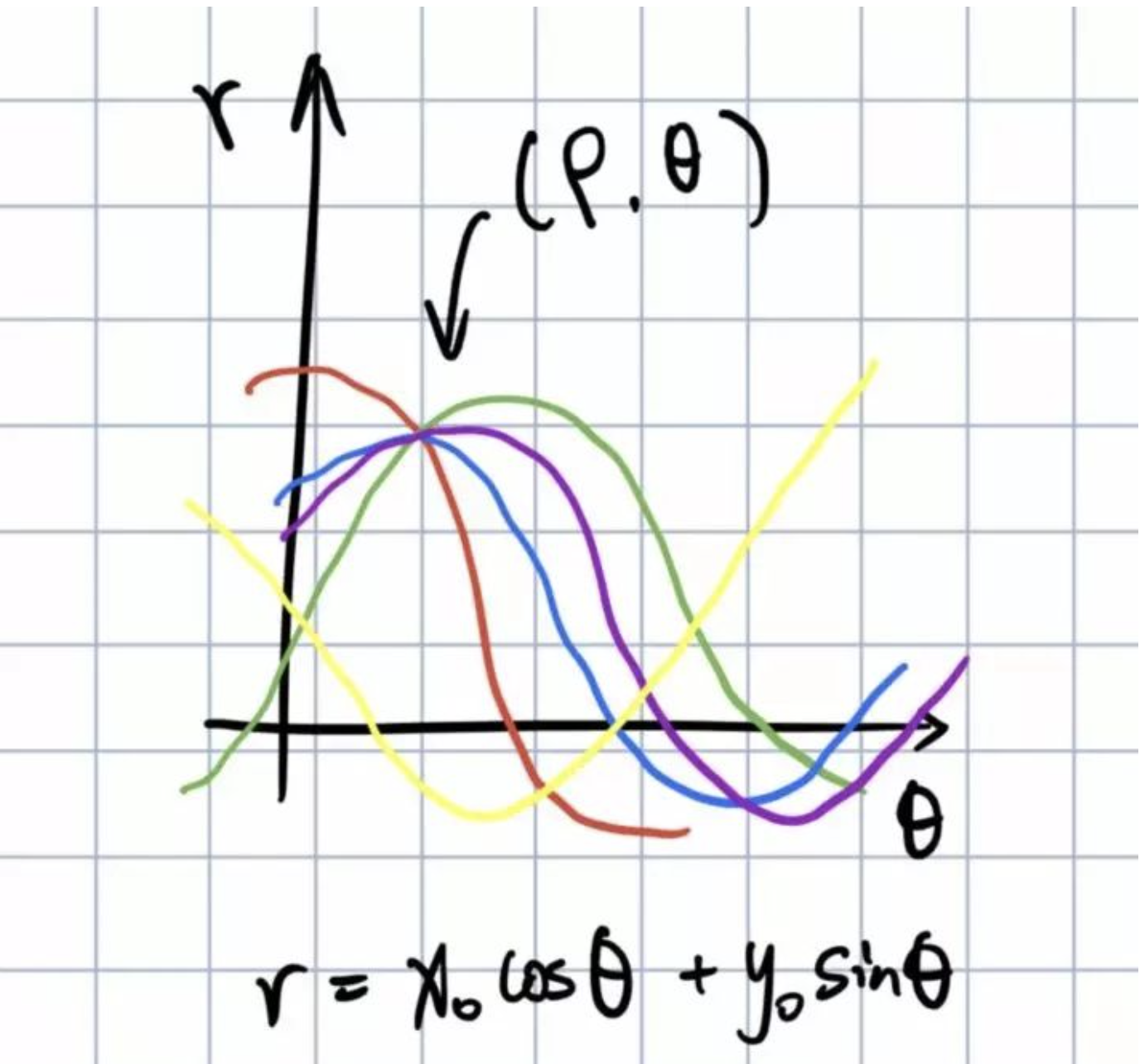
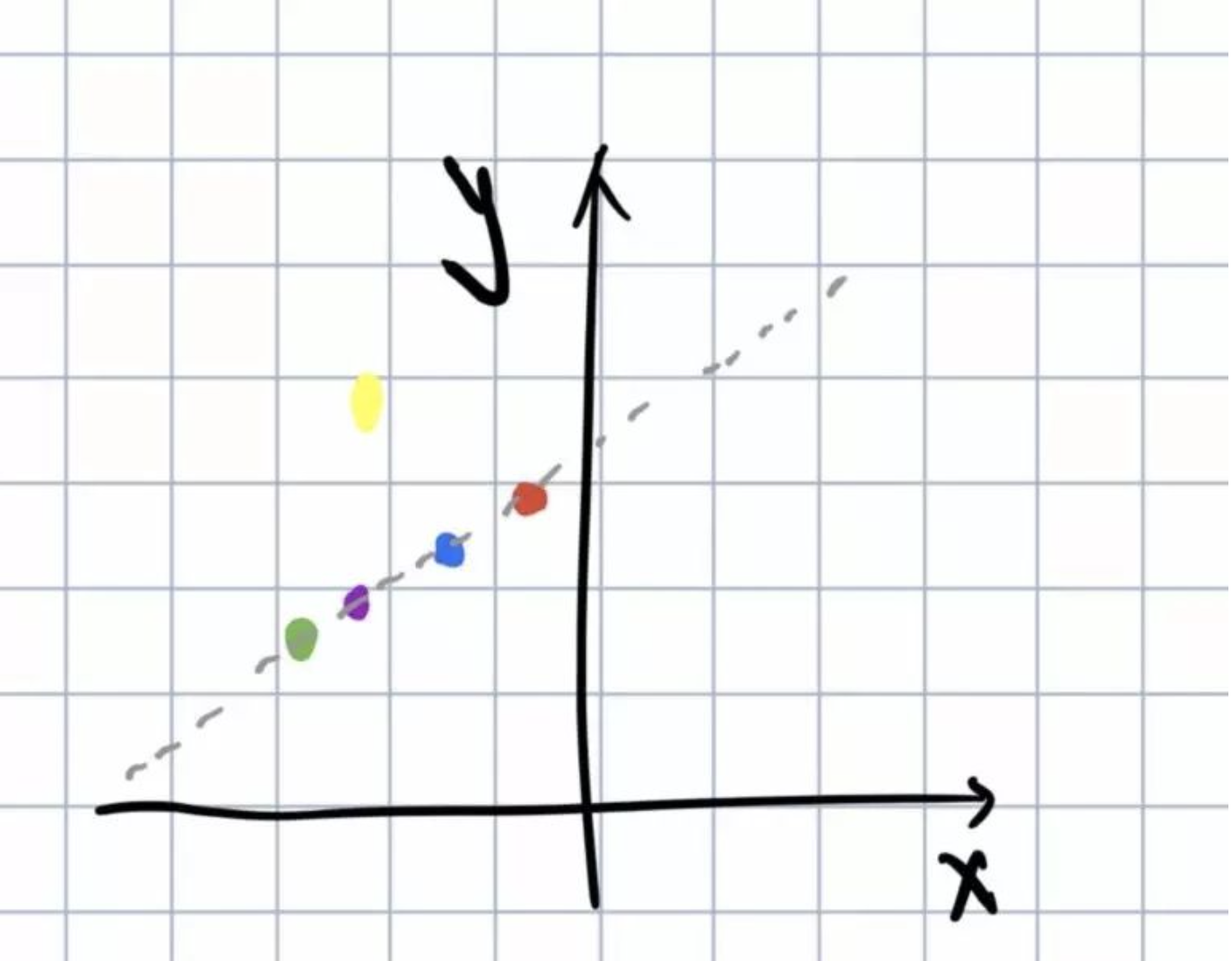
原图上红色紫色绿色蓝色的点对应的变换曲线相交在同一个点上,这个点对应的原点距和角方向就是原图中的四个点所在的直线的方向:
这意味着一般来说, 一条直线能够通过在平面($\theta$,$r_\theta$)上寻找交于一点的曲线数量来检测。 越多曲线交于一点也就意味着这个交点表示的直线由更多的点组成. 一般来说我们可以通过设置直线上点的 阈值 来定义多少条曲线交于一点我们才认为 检测 到了一条直线。
- 代码参考
- OpenCV接口
圆形变换
- 基本思想
跟霍夫直线检测一样,同样的原理,可以用于检测圆,只是对于圆的方程。
$(x –a ) ^2 + (y-b) ^ 2 = r^2$
其中(a,b)代表圆心,r是圆的半径
依旧是把图像空间转换成参数空间,这里是将X-Y平面转化成a-b-r参数空间,则在图像空间中的一个过(x,y)点的圆,对应参数空间中高度变化的三维锥面。
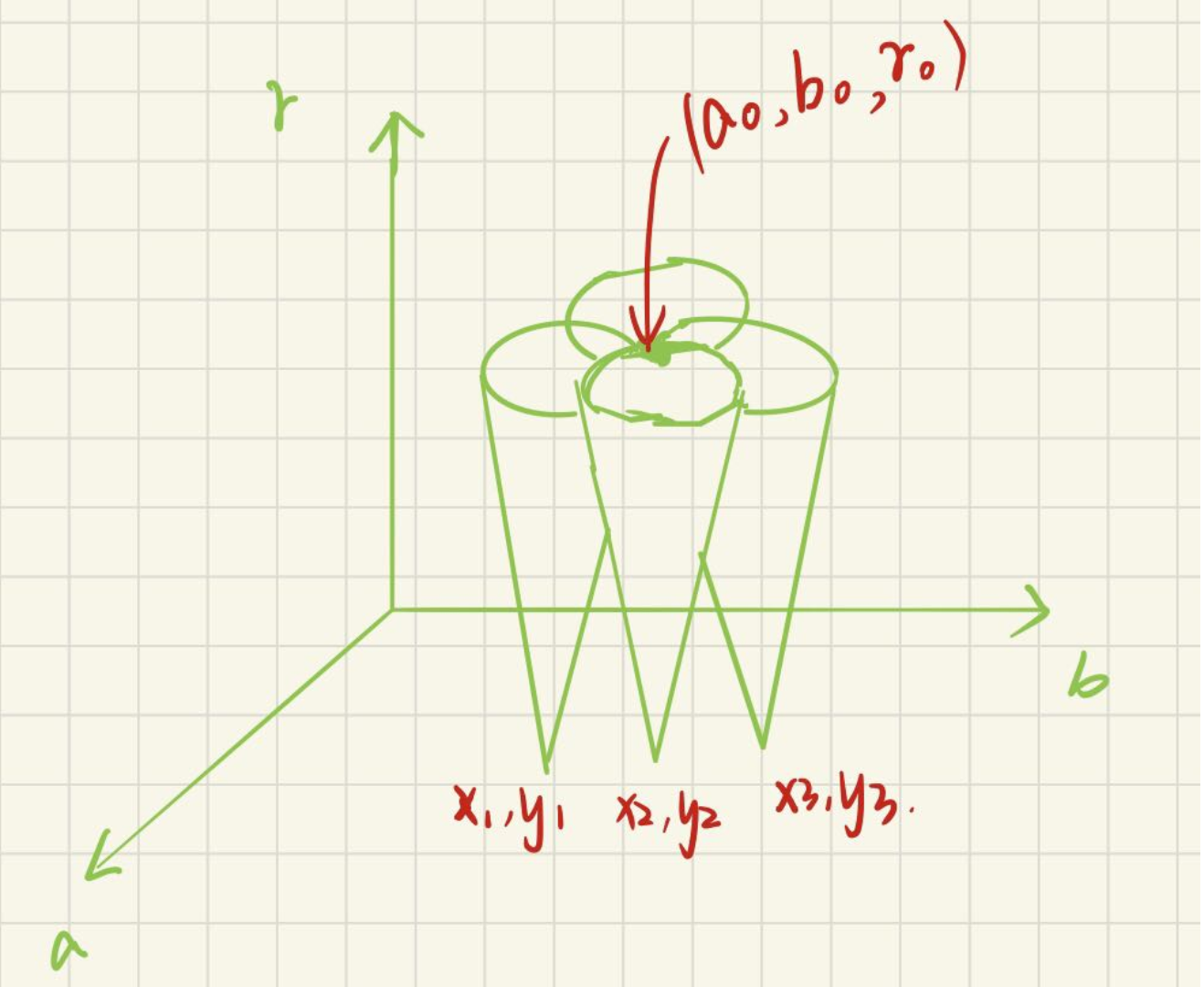
同理,过图像空间的任意一点的圆都对应于参数空间的一个三维锥面,因此,过图像空间上同一圆的点,对应的参数空间中的三维锥面,在r平面必然相交于一点(a,b,r),这样通过这一点就可以得到一个圆的参数。
- 详细推导
在极坐标系下,假设圆心为$(𝑥0,𝑦0)$,圆上的点可以表示为:
$𝑥=𝑥0+𝑟𝑐𝑜𝑠𝜃,𝑦=𝑦0+𝑟𝑠𝑖𝑛𝜃$
对于一个圆,假如中心像素点$(𝑥0,𝑦0)$,半径r已知,那么旋转360°,圆上的所有点就可以求得。同样,假如圆上的所有点,半径r已知,旋转360°,则会得到一个累加的极值点,那么这个点就是圆心了。
- 21HT的具体步骤:
第一阶段:检测圆心
1.1、对输入图像边缘检测(Canny);
1.2、计算图形的梯度,并确定圆周线,其中圆周的梯度就是它的法线;
1.3、在二维霍夫空间内,绘出所有图形的梯度直线,某坐标点上累加和的值越大,说明在该点上直线相交的次数越多,也就是越有可能是圆心;
1.4、在霍夫空间的4邻域内进行非最大值抑制;
1.5、设定一个阈值,霍夫空间内累加和大于该阈值的点就对应于圆心。
第二阶段:检测圆半径
2.1、计算某一个圆心到所有圆周线的距离,这些距离中就有该圆心所对应的圆的半径的值,这些半径值当然是相等的,并且这些圆半径的数量要远远大于其他距离值相等的数量;
2.2、设定两个阈值,定义为最大半径和最小半径,保留距离在这两个半径之间的值,这意味着我们检测的圆不能太大,也不能太小;
2.3、对保留下来的距离进行排序;
2.4、找到距离相同的那些值,并计算相同值的数量;
2.5、设定一个阈值,只有相同值的数量大于该阈值,才认为该值是该圆心对应的圆半径;
2.6、对每一个圆心,完成上面的2.1~2.5步骤,得到所有的圆半径。
- OpenCV接口
void HoughCircles(InputArray image,OutputArray circles, int method, double dp, double minDist, double param1=100, double param2=100, int minRadius=0,int maxRadius=0 )
image为输入图像,要求是灰度图像
circles为输出圆向量,每个向量包括三个浮点型的元素——圆心横坐标,圆心纵坐标和圆半径
method为使用霍夫变换圆检测的算法,Opencv2.4.9只实现了2-1霍夫变换,它的参数是CV_HOUGH_GRADIENT
dp为第一阶段所使用的霍夫空间的分辨率,dp=1时表示霍夫空间与输入图像空间的大小一致,dp=2时霍夫空间是输入图像空间的一半,以此类推
minDist为圆心之间的最小距离,如果检测到的两个圆心之间距离小于该值,则认为它们是同一个圆心
param1为边缘检测时使用Canny算子的高阈值
param2为步骤1.5和步骤2.5中所共有的阈值
minRadius和maxRadius为所检测到的圆半径的最小值和最大值